Kernel Memory 入门系列: Embedding 简介
在 RAG模式 其实留了一个问题。
我们对于的用户问题的理解和文档的检索并没有提供合适的方法。
当然我们可以通过相对比较传统的方法。
例如对用户的问题进行关键词提取,然后通过关键词检索文档。这样的话,就需要我们提前对文档做好相关关键词的标注,同时也需要关键词能够覆盖到用户可能的提出方式以及表达方法。这样的话,就需要我们对用户的问题有一个很好的预测。用户也需要在提问的时候,能够按照我们的预期进行提问。我们和用户双向猜测,双向奔赴,如果猜对了,那么就可以得到一个比较好的结果。如果猜错了,结果难以想象。
那么有没有一种方法,能够让我们不需要对用户的问题进行预测,也不需要对文档进行关键词标注,就能够得到一个比较好的结果呢?
这个答案就是 Embedding。
Embedding 是什么
Embedding 是一种将高维数据映射到低维空间的方法。在这个低维空间中,数据的相似性和原始空间中的相似性是一致的。这样的话,我们就可以通过低维空间中的相似性来进行检索。
通俗的理解,大语言模型基于大量的文本数据进行训练,得到了一个高维的向量空间,我们可以认为这是一个语义的空间。在这个语义空间中,每一个词或者每个句子都有一个对应的空间坐标。虽然这个坐标系的维度是非常高的,起码都是上百甚至上千的维度,但是我们仍可以想象在二维或者三维空间中的点去理解这个坐标。
然后,我们就可以通过这个向量来判断两段文字是否相似。如果两段文字的向量越接近,那么这两个词的语义就越接近。例如,猫 和 狗 的向量就会比 猫 和 苹果 的向量更加接近。
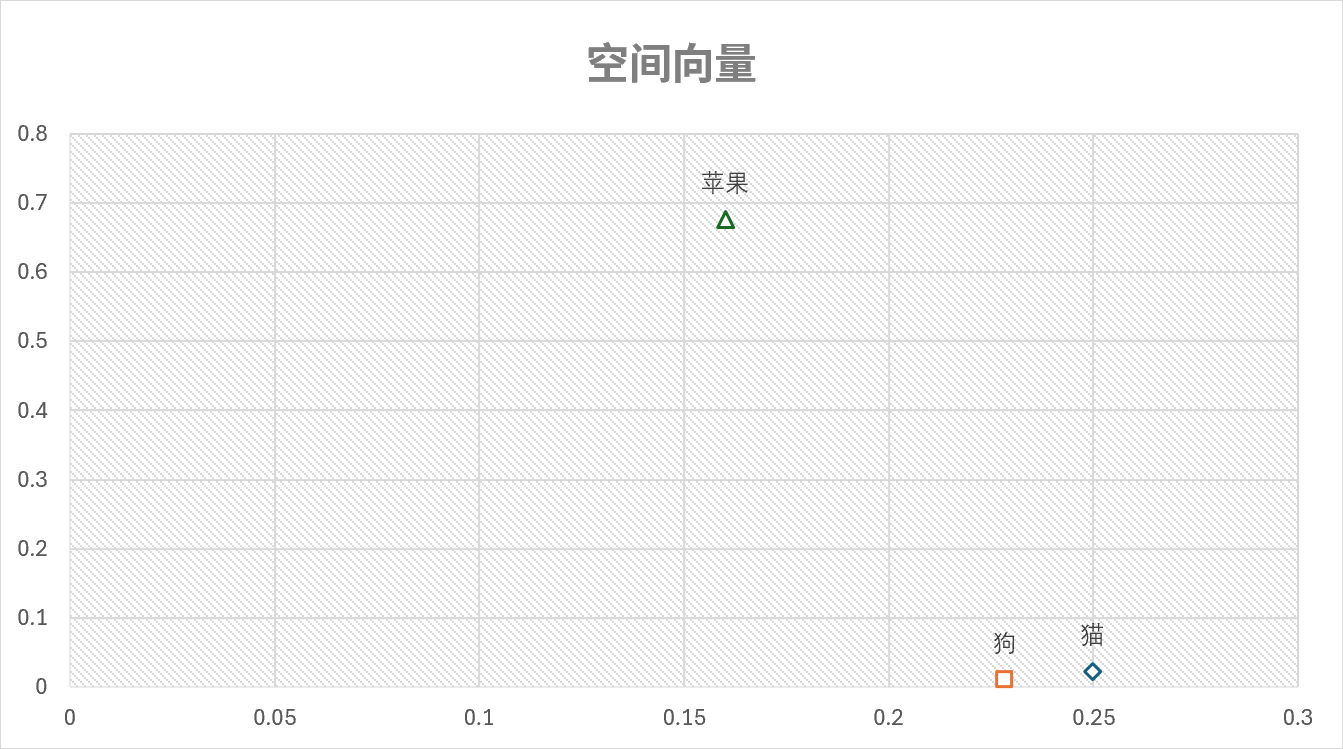
这个空间坐标和模型的关系更加密切,模型越强大,对于语义的理解越深刻,那么这个空间坐标的效果就越好。所以,寻找或者训练一个好的Embedding模型对于实现一个好的检索系统是非常重要的。
使用Embedding进行匹配
有了Embedding的结果之后,我们就可以看如何使用Embedding进行匹配了。
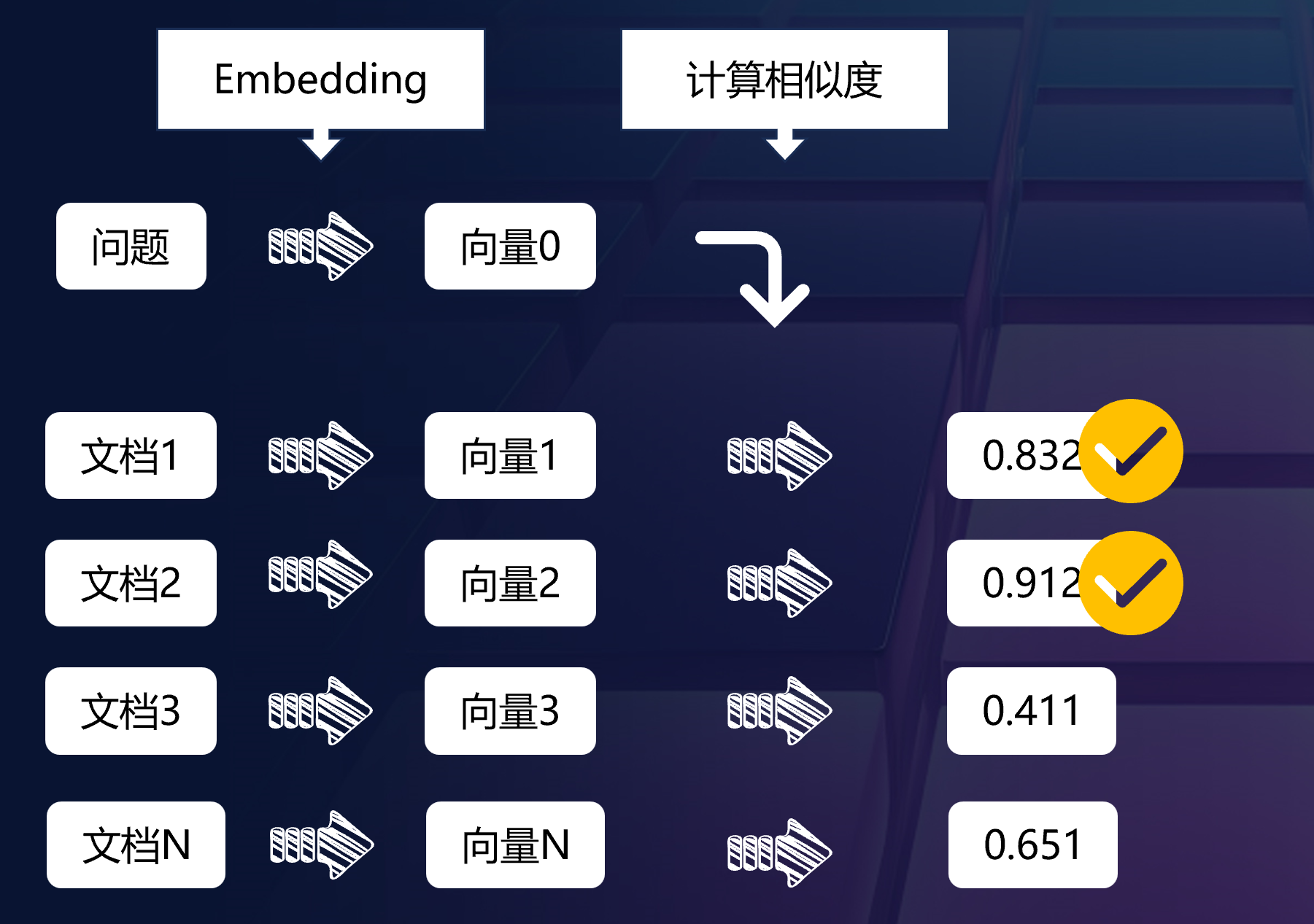
首先我们需要对用户的提问和我们的文本进行Embedding,得到对应的向量。
通过计算问题的向量与文本的向量的相似性,通常是余弦相似度计算,我们就可以得到一个排序的结果。这个排序的结果就是我们的检索结果。
根据实际模型的表现,选择合适的相似度阈值,然后就可以找到最为相似的内容了。
参考
嵌入基础知识
https://learn.microsoft.com/zh-cn/azure/ai-services/openai/how-to/embeddings?tabs=console
你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
了解如何使用 Azure OpenAI 生成嵌入
嵌入是一种特殊的数据表示格式,可由机器学习模型和算法轻松使用。 嵌入是一段文本的语义含义的信息密集表示。 每个嵌入是浮点数的一个向量,向量空间中两个嵌入之间的距离与原始格式的两个输入之间的语义相似性相关。 例如,如果两个文本相似,则它们的向量表示形式也应该相似。 嵌入在 Azure 数据库中支持矢量相似性搜索,例如 Azure Cosmos DB for MongoDB vCore 或 Azure Database for PostgreSQL - 灵活服务器。
如何获取嵌入
为了获取一段文本的嵌入向量,我们向嵌入终结点发出请求,如以下代码片段中所示:
console
1 | curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/deployments/YOUR_DEPLOYMENT_NAME/embeddings?api-version=2023-05-15\ |
OpenAI Python 0.28.1
1 | import openai |
OpenAI Python 1.x
1 | import os |
C#
1 | using Azure; |
PowerShell
1 | # Azure OpenAI metadata variables |
最佳实践
确认输入不超过最大长度
最新嵌入模型的输入文本的最大长度为 8192 个标记。 在发出请求之前,应确认输入未超过此限制。
限制和风险
在某些情况下,我们的嵌入模型可能不可靠或造成社会性风险,如果没有缓解措施,它们可能会造成损害。 请查看负责任的 AI 内容,获取有关如何以负责的形式使用这些模型的详细信息。
What are Embeddings?
https://learn.microsoft.com/en-us/semantic-kernel/memories/embeddings
Memory: Embeddings
- Embeddings are vectors or arrays of numbers that represent the meaning and the context of tokens processed by the model.
- They are used to encode and decode input and output texts, and can vary in size and dimension. / Embeddings can help the model understand the relationships between tokens, and generate relevant and coherent texts.
- They are used for text classification, summarization, translation, and generation, as well as image and code generation.
Notes generated by plugin SummarizePlugin.Notegen
Embeddings are the representations or encodings of tokens, such as sentences, paragraphs, or documents, in a high-dimensional vector space, where each dimension corresponds to a learned feature or attribute of the language. Embeddings are the way that the model captures and stores the meaning and the relationships of the language, and the way that the model compares and contrasts different tokens or units of language. Embeddings are the bridge between the discrete and the continuous, and between the symbolic and the numeric, aspects of language for the model.
What are embeddings to a programmer?
Embeddings are vectors or arrays of numbers that represent the meaning and the context of the tokens that the model processes and generates. Embeddings are derived from the parameters or the weights of the model, and are used to encode and decode the input and output texts. Embeddings can help the model to understand the semantic and syntactic relationships between the tokens, and to generate more relevant and coherent texts. Embeddings can also enable the model to handle multimodal tasks, such as image and code generation, by converting different types of data into a common representation. Embeddings are an essential component of the transformer architecture that GPT-based models use, and they can vary in size and dimension depending on the model and the task.
How are embeddings used?
Embeddings are used for:
- Text classification: Embeddings can help the model to assign labels or categories to texts, based on their meaning and context. For example, embeddings can help the model to classify texts as positive or negative, spam or not spam, news or opinion, etc.
- Text summarization: Embeddings can help the model to extract or generate the most important or relevant information from texts, and to create concise and coherent summaries. For example, embeddings can help the model to summarize news articles, product reviews, research papers, etc.
- Text translation: Embeddings can help the model to convert texts from one language to another, while preserving the meaning and the structure of the original texts. For example, embeddings can help the model to translate texts between English and Spanish, French and German, Chinese and Japanese, etc.
- Text generation: Embeddings can help the model to create new and original texts, based on the input or the prompt that the user provides. For example, embeddings can help the model to generate texts such as stories, poems, jokes, slogans, captions, etc.
- Image generation: Embeddings can help the model to create images from texts, or vice versa, by converting different types of data into a common representation. For example, embeddings can help the model to generate images such as logos, faces, animals, landscapes, etc.
- Code generation: Embeddings can help the model to create code from texts, or vice versa, by converting different types of data into a common representation. For example, embeddings can help the model to generate code such as HTML, CSS, JavaScript, Python, etc.