Kernel Memory 入门系列: RAG 简介
开一个新坑,Semantic Kernel系列会在 Release 1.0 之后陆续更新。
当我们有了一定的产品资料或者知识内容之后,自然想着提供一个更加方便的方式让用户能够快速地找到自己想要的信息,或者得到一个更加智能的答案。
以往的时候可能需要通过一些搜索引擎或者问答系统来实现,但是这些系统往往需要极高的维护成本,而且对于用户来说也不是很友好。很多时候仍然需要用户自己去思考问题的表达方式,然后再去搜索或者提问,可以说是费事费力。
如今有了大语言模型,我们就可以考虑通过它来实现一个更加智能的问答系统,为用户提供一个更加友好的交互方式。
从对话开始
当我们直接接入大语言的模型的时候,往往会遇到一个很常见的问题,就是它对于我们私有的数据,小众领域的信息或者较新的知识并不知道。

这源自于大语言模型的训练数据集的限制,它的数据往往来自于大众的语料库,所以对于公开的信息了解的就比较多,但是对于私有的数据,小众领域的信息都不在它的知识范围内,而且由于训练成本和时间的限制,它也不可能实时地去更新模型本身的知识。
这个时候得到“不知道”的答案反而是一个好事儿,起码看得出来这个模型是有一定的智能的,它知道自己不知道,而不是随便瞎猜。毕竟处理大模型的幻觉也是很大的一个问题。
补充上下文
那么这个时候如果想要让模型能够为我们所用的,就需要上一点技术手段了。
最简单的方法就是在与大模型沟通的时候,增加一些上下文的信息。

那这里的上下文就是我们所能够提供给模型的,用于回答用户问题的信息了。
那么接下来的问题就是,这个上下文信息是怎么来的?
RAG
我们需要从整个流程来回溯一下:
- 1.首先用户提出问题,这个问题从始至终不会发生变化
- 2.然后我们需要理解用户的问题,知道用户提问的意图和方向
- 3.接下来就是我们需要根据用户的问题,去检索我们的知识库,找到与用户问题相关的信息,查找出与之相关的的文档或者文本内容
- 4.最后我们需要将这些文档或者文本内容进行整合,组成一个完整的提示词,提供给大语言模型用于生成
- 5.最后通过大语言模型生成相对精确的答案,返回给用户

这个过程就被称为 RAG(Retrieval Augmented Generation),也就是检索增强生成。
参考资料
检索增强生成 (RAG)
通用语言模型通过微调就可以完成几类常见任务,比如分析情绪和识别命名实体。这些任务不需要额外的背景知识就可以完成。
要完成更复杂和知识密集型的任务,可以基于语言模型构建一个系统,访问外部知识源来做到。这样的实现与事实更加一性,生成的答案更可靠,还有助于缓解“幻觉”问题。
Meta AI 的研究人员引入了一种叫做检索增强生成(Retrieval Augmented Generation,RAG)的方法来完成这类知识密集型的任务。RAG 把一个信息检索组件和文本生成模型结合在一起。RAG 可以微调,其内部知识的修改方式很高效,不需要对整个模型进行重新训练。
RAG 会接受输入并检索出一组相关/支撑的文档,并给出文档的来源(例如维基百科)。这些文档作为上下文和输入的原始提示词组合,送给文本生成器得到最终的输出。这样 RAG 更加适应事实会随时间变化的情况。这非常有用,因为 LLM 的参数化知识是静态的。RAG 让语言模型不用重新训练就能够获取最新的信息,基于检索生成产生可靠的输出。
Lewis 等人(2021)提出一个通用的 RAG 微调方法。这种方法使用预训练的 seq2seq 作为参数记忆,用维基百科的密集向量索引作为非参数记忆(使通过神经网络预训练的检索器访问)。这种方法工作原理概况如下:
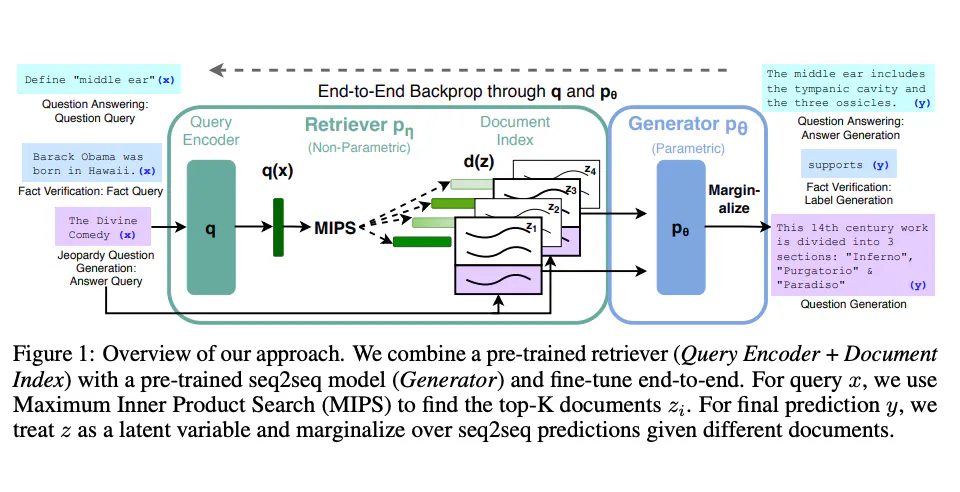
- 图片援引自: Lewis et el. (2021)
RAG 在 Natural Questions、WebQuestions 和 CuratedTrec 等基准测试中表现抢眼。用 MS-MARCO 和 Jeopardy 问题进行测试时,RAG 生成的答案更符合事实、更具体、更多样。FEVER 事实验证使用 RAG 后也得到了更好的结果。
这说明 RAG 是一种可行的方案,能在知识密集型任务中增强语言模型的输出。
最近,基于检索器的方法越来越流行,经常与 ChatGPT 等流行 LLM 结合使用来提高其能力和事实一致性。
LangChain 文档中可以找到一个使用检索器和 LLM 回答问题并给出知识来源的简单例子。