Kernel Memory 入门系列:Semantic Kernel 插件
Kernel Memory 入门系列:Semantic Kernel 插件Kernel Memory 本身提供了完整的RAG能力,这部分能力如果通过Semantic Kernel Memory的话,也是可以实现的,但是整体的管理成本会比较高。
因此通过Kernel Memory 构建知识库管理,然后通过插件的方式,将Kernel Memory接入到Semantic Kernel 中,这样就可以有效的提升整体的使用效率。
初始化插件首先需要在Semantic Kernel 的项目中添加对应的Kernel Memory的Semantic Kernel Plugin包。
1dotnet add package Microsoft.KernelMemory.SemanticKernelPlugin
然后就取出构建KernelMemory,构建的步骤和之前的方式一样,也可以使用Kernel Memory Service的 WebClient.
123456var memory = new KernelMemoryBuilder() //... ...

Kernel Memory 入门系列:自定义处理流程
Kernel Memory 入门系列:自定义处理流程在整个文档预处理的流程中,涉及到很多的处理步骤,例如:文本提取,文本分片,向量化和存储。这些步骤是Kernel Memory中的默认提供的处理方法,如果有一些其他的需求,也可以进行过程的自定义。
自定义Handler在Kernel Memory中,可以通过自定义Handler的方式来实现自定义的处理流程。自定义Handler需要实现IPipelineStepHandler接口,该接口定义如下:
123456public interface IPipelineStepHandler{ string StepName { get; } Task<(bool success, DataPipeline updatedPipeline)> InvokeAsync(DataPipeline pipeline, CancellationToken cancellationToken = default);}
其中,StepName是自定义Handler的名称,用于在Pipelin ...

Kernel Memory 入门系列:文档的管理
Kernel Memory 入门系列: 文档的管理在Quick Start中我们了解到如何快速直接地上传文档。但是实际中,往往会面临更多的问题,例如文档如何更新,如何划定查询范围等等。这里我们将详细介绍在Kernel Memory文档的管理。
使用Document管理一组文件当我们需要批量上传一组文件的时候,可以使用Document来管理。
1234var document = new Document();document.AddFile("./sample-SK-Readme.pdf");document.AddFile("./sample-KM-Readme.md");await memory.ImportDocumentAsync(document);
其中Document 作为一个对象,可以将多个文件归结到一起,可以自行指定对应的DocumentId,如果不指定的话,会生成一个随机的DocumentId,这个DocumentId后续可以用来查询文档的处理状态或者用于更新删除文档。
后续的使用和管理,将会以Document为基本的文档单 ...
Kernel Memory 入门系列:生成并获取文档摘要
Kernel Memory 入门系列:生成并获取文档摘要前面在RAG和文档预处理的流程中,我们得到一个解决方案,可以让用户直接获取最终的问题答案。
但是实际的业务场景中,仍然存在一些基础的场景,不需要我们获取文档的所有详情的,而只是了解的文档的大概信息,得到文章整体的摘要或者总结,此时仍然可以使用Kernel Memory来处理。
生成摘要我们依然使用Kernel Memory的文件导入方法,不过此时不需要指定默认的处理流程,而只需要指定Summary流程即可。
1234await memory.ImportDocumentAsync(new Document("doc1") .AddFile("file4-SK-Readme.pdf") .AddFile("file5-NASA-news.pdf"), steps: Constants.PipelineOnlySummary);
其中PipelineOnlySummary 包含了一下步骤:
extract
summarize
gen_em ...

Kernel Memory 入门:Quick Start
Kernel Memory 入门:Quick Start了解了用户问答和文档预处理的流程之后,我们就可以直接开始使用Kernel Memory了。
1. 安装项目中只需要通过NuGet安装Microsoft.KernelMemory.Core包即可。
1dotnet add package Microsoft.KernelMemory.Core
2. 构建Kernel Memory的构建过程非常简单,只需要调用KernelMemoryBuilder的Build方法即可。
123var memory = new KernelMemoryBuilder() .WithOpenAIDefaults(Env.Var("OPENAI_API_KEY")) .Build<MemoryServerless>();
其中默认需要配置LLM和Embedding服务,如果使用OpenAI的服务,可以只需要通过WithOpenAIDefaults方法传入OpenAI的API Key即可。
默认使用的是gpt- ...

Kernel Memory 入门系列:文档预处理
Kernel Memory 入门系列:文档预处理Embedding为我们提供了问题理解和文档检索的方法,但是面对大量的文档,如果在用于提问的时候再进行文档的Embedding的话,那这个过程是非常耗时的,再加之我们的文档并不会频繁变化,所以我们可以对文档进行预处理,提升检索的效率。
文档的预处理大致分为了几个步骤:
1.文档的准备
首先需要把我们已有的文档整理出来,起码是需要进行检索的这些文档。文档的格式不会有很大的限制,可以是docx,也可以是pdf或者ppt,当然也可以是txt或者markdown,哪怕是图片、网页或者其他可以提取文本的文档格式都可以。
2.文本的提取
文本提取的过程,就是将已经整理好的文档中的文字提取出来,根据不同的文档类型匹配相应的提取方法。Kernel Memory中已经默认集成了docx、excel、ppt、pdf、plaintext(markdown、text)、json、image(via OCR)等类型的文本提取方法,如果有其他的文档类型,也可以自行添加。
3.文本的分片
我们的文档往往比较大,如果直接进行检索使用的话,会导致最终的提示词上 ...

Kernel Memory 入门系列:Embedding 简介
Kernel Memory 入门系列: Embedding 简介在 RAG模式 其实留了一个问题。
我们对于的用户问题的理解和文档的检索并没有提供合适的方法。
当然我们可以通过相对比较传统的方法。
例如对用户的问题进行关键词提取,然后通过关键词检索文档。这样的话,就需要我们提前对文档做好相关关键词的标注,同时也需要关键词能够覆盖到用户可能的提出方式以及表达方法。这样的话,就需要我们对用户的问题有一个很好的预测。用户也需要在提问的时候,能够按照我们的预期进行提问。我们和用户双向猜测,双向奔赴,如果猜对了,那么就可以得到一个比较好的结果。如果猜错了,结果难以想象。
那么有没有一种方法,能够让我们不需要对用户的问题进行预测,也不需要对文档进行关键词标注,就能够得到一个比较好的结果呢?
这个答案就是 Embedding。
Embedding 是什么Embedding 是一种将高维数据映射到低维空间的方法。在这个低维空间中,数据的相似性和原始空间中的相似性是一致的。这样的话,我们就可以通过低维空间中的相似性来进行检索。
通俗的理解,大语言模型基于大量的文本数据进行训练,得到了一个高维的向量空间, ...
Kernel Memory 入门系列:RAG 简介
Kernel Memory 入门系列: RAG 简介开一个新坑,Semantic Kernel系列会在 Release 1.0 之后陆续更新。
当我们有了一定的产品资料或者知识内容之后,自然想着提供一个更加方便的方式让用户能够快速地找到自己想要的信息,或者得到一个更加智能的答案。
以往的时候可能需要通过一些搜索引擎或者问答系统来实现,但是这些系统往往需要极高的维护成本,而且对于用户来说也不是很友好。很多时候仍然需要用户自己去思考问题的表达方式,然后再去搜索或者提问,可以说是费事费力。
如今有了大语言模型,我们就可以考虑通过它来实现一个更加智能的问答系统,为用户提供一个更加友好的交互方式。
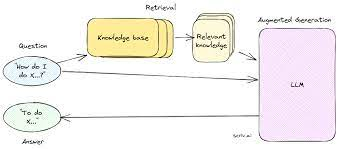
从对话开始当我们直接接入大语言的模型的时候,往往会遇到一个很常见的问题,就是它对于我们私有的数据,小众领域的信息或者较新的知识并不知道。
这源自于大语言模型的训练数据集的限制,它的数据往往来自于大众的语料库,所以对于公开的信息了解的就比较多,但是对于私有的数据,小众领域的信息都不在它的知识范围内,而且由于训练成本和时间的限制,它也不可能实时地去更新模型本身的知识。
这个时候得到“不知道”的答案反而是 ...

程序员的自我修养-性能优化
本文聊一个程序员都会关注的问题:性能。
当大家谈到“性能”时,你首先想到的会是什么?
是每次请求需要多长时间才能返回?
是每秒钟能够处理多少次请求?
还是程序的CPU和内存使用率高不高?
这些问题基本上反应了性能关注的几个主要方面:响应时间、吞吐量和资源利用率。在这三个方面中,如果能够实现更低的响应时间和更高的吞吐量,那么资源利用率也必然得到优化。这是因为我们的工作总是在有限的硬件、软件、时间和预算等的约束下进行的,而优化前两个方面将有助于更有效地利用这些资源。
因此,本文将主要围绕响应时间和吞吐量的优化展开介绍,包括相关领域的定义和软硬件方面的优化方法。
响应时间想象一下,你在餐厅点了一道菜,响应时间就是从你下单到菜品送到你面前的这段时间。
在计算机里,它指的是单次请求或指令处理的时间。
1.1 软件层面的优化软件层面的优化主要是通过减少非必要的处理来降低响应时间,包括减少IO请求和优化代码逻辑。
1.1.1 减少IO请求
减少IO请求的意义
IO就是输入输出,减少IO处理就是减少对输入输出设备的访问。在计算机中,除了CPU和内存,其它的键盘、鼠标、显示器、音响、硬盘、 ...

C++ 核心指南之资源管理(下)智能指针最佳实践
C++ 核心指南之资源管理(下)智能指针最佳实践C++ 核心指南(C++ Core Guidelines)是由 Bjarne Stroustrup、Herb Sutter 等顶尖 C+ 专家创建的一份 C++ 指南、规则及最佳实践。旨在帮助大家正确、高效地使用“现代 C++”。
这份指南侧重于接口、资源管理、内存管理、并发等 High-level 主题。遵循这些规则可以最大程度地保证静态类型安全,避免资源泄露及常见的错误,使得程序运行得更快、更好。
R.smart:智能指针
R.20:使用 unique_ptr 或 shared_ptr 来表示所有权
R.21:除非需要共享所有权,否则优先使用 unique_ptr 而不是 shared_ptr
R.22:使用 make_shared() 创建 shared_ptr
R.23:使用 make_unique() 创建 unique_ptr
R.24:使用 std::weak_ptr 打破 shared_ptr 的循环引用
R.30: 仅在需要明确表示生命周期语义时才将智能指针作为参数传递
R.31: 如果你使用的是非 std 智能指针, ...